Recently in one of the discussions I heard a statement – “for our solution, we require near 100% availability”. But do we really understand, what’s near 100% really means. For me, anything above 99% is near 100. But in reality, there is huge difference in 99% availability and 99.9999% availability.
Let’s look at definition of Availability – “Availability is the percentage of time that the infrastructure, system or a solution remains operational under normal circumstances in order to serve its intended purpose.”
The mathematical formula for Availability is: Percentage of availability = (total elapsed time – sum of downtime)/total elapsed time
That means, for an SLA of 99.999 percent availability (the famous five nines), the yearly service downtime could be as much as 5.256 minutes.
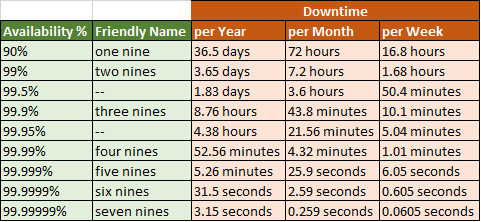
As an IT leader, we should be aware of differences between nines’ and define requirements properly for the development team. As higher the nines, higher will be operational and development cost.
Another statement I heard during discussion – “cloud provider mostly provides 99.95% availability, so our system also provides same.”. Really? That may be true, if you are using SaaS solution from any of the cloud provider. But if you are developing your own solution over any cloud provider’s IaaS or PaaS services, then consider following two things,
- SLA defined by cloud providers is of their individual services only. That means, combined SLA need to be calculated based on cloud services you have consumed within your solution. We will further see how this is calculated in the next section.
- Suppose you are using only PaaS services in your solution, then you still own Application and Data layer, any bug or issue in your code, will result in non-availability. That also need to be considered while calculating your solution availability.
Combined SLA for consumed cloud services
Suppose you are developing a simple web application using Azure PaaS services, such as Azure App Service and Azure SQL Database. Taken in isolation, these services usually provide something in the range of three to four nines of availability,
- Azure App Service: 99.95%
- Azure SQL Database: 99.99%
- Azure Traffic Manager: 99.99%
However, when these services are combined within architecture there is possibility that any one component could suffer an outage, bringing overall solution availability lower than individual availability.
Services in Serial
In following example where App Service and SQL Database are connected in serial, each service is a failure mode. There could be three possibilities of failure,
- App Service may go down, SQL Database may still be up and running
- App Service may be up and running, SQL Database may go down
- Both App Service and SQL Database may go down together

So, to calculate combines availability for serial connected services, simply multiply individual availability percentage, i.e.
Availability of App Service * Availability of SQL Database
=
99.95% * 99.99%
=
99.94%
Observation – combined availability of 99.94% is lesser than individual services availability.
Services in Parallel
Now to make this solution highly available, you can have same replica of this solution deployed in another region and add traffic manager to dynamically redirect traffic into one of the region. This may add larger failure modes, but we will see how it will enhance/increase solution availability.
As we calculated,
- Availability across services in Region A = 99.94%
- Availability across services in Region B (replica of Region A) = 99.94%
Both Region A and Region B are parallel to each other. So, to calculate combined availability for parallel services, use following formula,
1 – ((1 – Region-A availability) * (1 – Region-B Availability))
=
1 – ((1 – 99.4%) * (1 – 99.4%))
=
99.9999%

Also observe, Traffic Manager is in series to both parallel regions. So combines solution availability will be,
Availability of Traffic Manager * Combined availability of both regions
=
99.99% * 99.9999%
=
99.99 %
Observation – we are able to increase availability from three nines to four nines by adding a new region in parallel.
Please note, above is the combined availability of services (you have chosen) provided by Azure. This availability doesn’t include your custom code. Remember following diagram, which explains what is owned by cloud providers and what is owned by you based on cloud platform you choose,

Going back to our web application example, using App Services and SQL Database, we have opted for PaaS platform. In that case, the availability we have calculated is from Runtime to Networking layers, which doesn’t include your custom code for Applications and Data layers. So those layers you still must design for high availability. You can refer some of the following techniques, which are useful while designing for high availability solution,
- Auto-scaling – design solution to increase and decrease instances, based on active load
- Self-Healing – dynamically identify failures and redirect traffic to healthy instances
- Exponential backoff – implement retries on the requester side, this simple technique increases the reliability of the application, and takes care of intermittent failures
- Broker pattern – implement message passing architecture using queues and allow decoupling of components
The price of availability
Please remember one thing, availability has a cost associated with it. The more available your solution need to be, the more complexity is required, and so forth more expensive it will be.
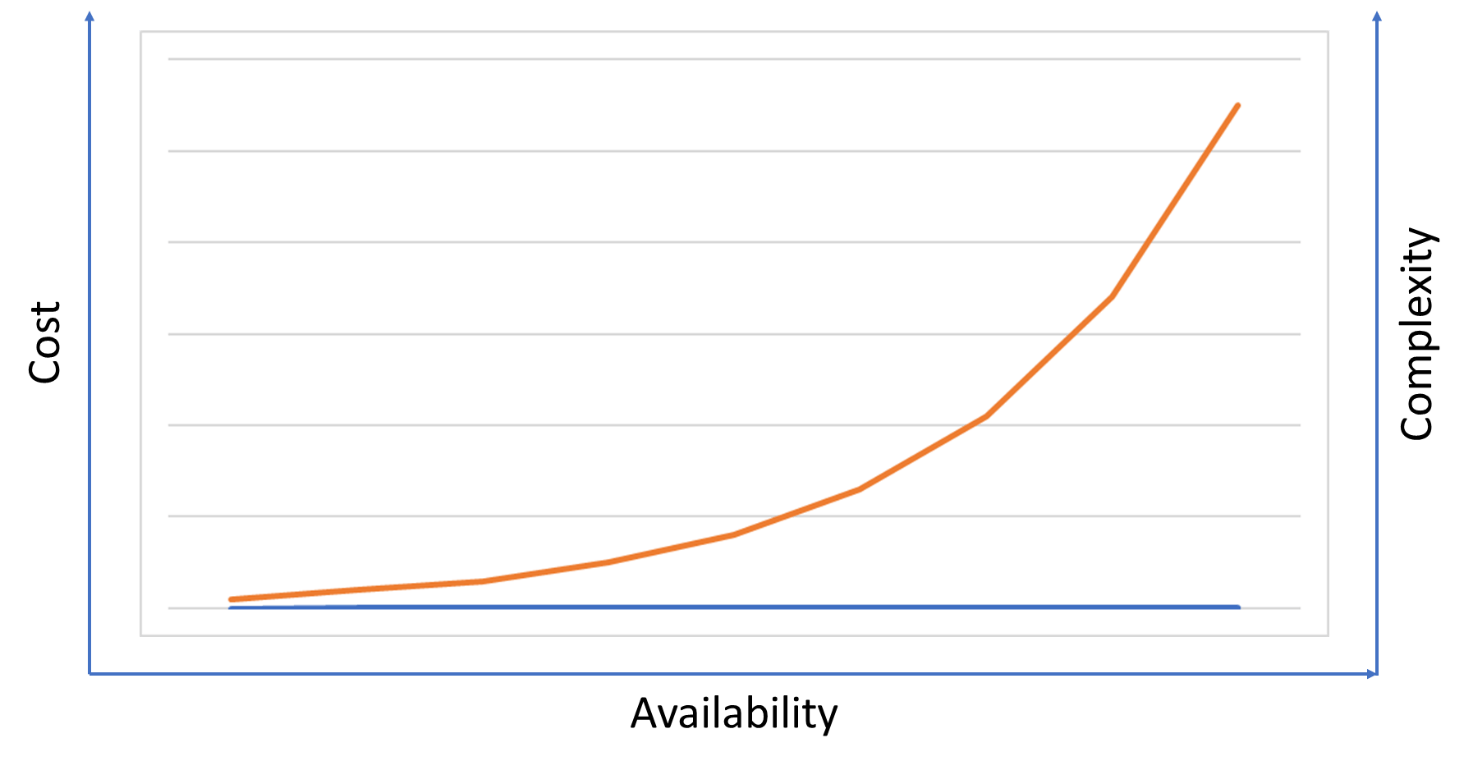
High available solution requires high degree of automation and self-healing capabilities, which requires significant development, testing and validation. This will require time, money and right resources, and all this will impact cost.
In the last, analyzing your system and calculating theoretical availability will help you understand your solution capabilities and help you take right design decisions. However, this availability can be highly affected by your ability to react to failures and recover the system, either manually or through self-healing processes.








Leave a comment